Challenge Overview
Problem Statement | |||||||||||||
Prize Distribution
Prize USD
1st $10,000
2nd $7,000
3rd $5,000
4th $4,000
5th $3,000
6th $2,000
7th $1,000
Week 1 bonus
1st $1,000
2nd $500
Week 2 bonus
1st $1,000
2nd $500
Total Prizes $35,000
Why this challenge mattersLung cancer is the leading cause of cancer death in the United States. Many lung cancer patients receive radiation therapy (delivery of beams of ionizing radiation focused directly at the tumor) and successful treatment depends heavily on the radiation oncologist's (doctor specializing in radiation treatments for lung cancer) ability to accurately identify and delineate the tumor's shape on medical imaging, to maximize the likelihood of killing the cancer and minimize injury to the surrounding organs. Furthermore, accurate and precise delineation of a lung tumor is important to assess changes of tumor size after treatment to understand the cancer's responsiveness to interventions. Manual delineation of tumors is very time consuming when performed by highly trained experts and is prone to inconsistency and bias. Automatic delineation also has issues because it depends heavily on the training data sets and tends to make errors, which are easily detected by experts. With your help we want to change this! The new Harvard Tumor Hunt challenge sponsored by the Crowd Innovation Lab and the Harvard Medical School tasks competitors to produce an automatic tumor delineation algorithm that parallels lung tumor delineation accuracy of an average expert, while exceeding the expert in processing speed and delineation consistency. The challenge will run in two stages. The first stage targets the accuracy of the algorithm, which must reproduce the delineation by the expert as closely as possible. The second will target credibility of the algorithm by using expert feedback to further train the algorithm to avoid the types of errors that a trained human would never make. The current contest corresponds to the first stage of the challenge. Further background information about the contest can be found at the Harvard Tumor Hunt Challenge Minisite. ObjectiveYour task will be to extract polygonal areas that represent tumor regions from CT scan images. The polygons your algorithm returns will be compared to ground truth data, the quality of your solution will be judged by how much your solution overlaps with the expected results, see Scoring for details. Input FilesIn this task you will work with anonymized CT scans. Data corresponding to a scan is made up of 3 components: it consists of several images (which represent horizontal cross sections, slices of the human body), textual meta data that gives information on how to interpret the image data (e.g. how to translate pixel coordinates into physical coordinates), and ground truth annotations of region contours that describe tumor regions or other regions of interest within the images. Region contour annotations are present only in the training data and removed from provisional and system testing data. Data for this contest is made available in two versions, a PNG-based and a DICOM (.DCM) - based. The content of these two versions are almost identical (there are some extra meta data fields in the DCM version that are not relevant for the current task), you may use either of them, whichever you are more comfortable working with. Note, however that the visualizer that comes with the challenge can work only with the PNG version. The two versions are described below in more detail. Some of the information given for the PNG version is valid for both versions so it is recommended to read it even if you choose to work with the DCM version. PNG data versionData corresponding to a scan is organized into the following file structure:
/<scan_id>
structures.dat
/auxiliary
<slice_id>.dat
/contour
<slice_id>.<structure_id>.dat
/pngs
<slice_id>.png
Where
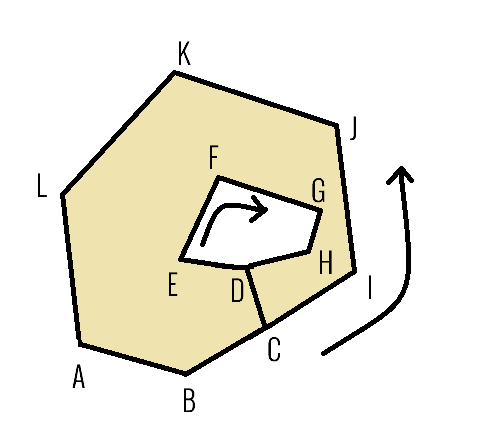
The 3 data components of a scan are described in more detail below. Images Scan slices are grayscale PNG images with 16 bit per pixel color depth. They can be found in the /pngs directory, the name of the file contains the slice identifier. They can be opened by most image viewers, however - depending on the image viewer application you use - most of the images will appear almost completely black, because typically only the 0 - 2000 gray value range is present from the full range of 0 - 65535. If you want to actually look at the content, you need to brighten the images, or use an image viewer that automatically scales up the brightness values, or use the visualizer tool that comes with the challenge. The number of images per scan varies between 36 and 371 (inclusive). All images in this contest will be of size 512x512 pixels. Image metadata Metadata are described in text files in the /auxiliary folder. Again, the name of the file contains the slice identifier. The file contains (key, value list) pairs, one per line, where keys and elements of the value list are separated by commas. The keys correspond to standard Dicom tags. See the ct_tags.txt file for more information. Contours The location and shape of known regions on images are referred to as 'ground truth' in this document. These data are described in text files found in the /contours folder. Note that contour descriptions are present only in the training data. The name of such files are in the form <slice_id>.<structure_id>.dat where <slice_id> references an image of the scan and <structure_id> references a named structure that a radiologist marked up on the image. The mapping of structure_ids to names is given in the structures.dat text file that contains a pipe ('|')-separated list of structure names. The nth entry in this list (1-based) corresponds to <structure_id> 'n'. For example if the list contains BODY|right_lung|left_lung|radiomics_gtv|radiomics_ln_sum then contour files with name <slice_id>.3.dat will describe the shape of the left lung. In this contest the most important structures are named "radiomics_gtv", these are the lung tumor regions that your algorithms must learn to identify. All other structures are given only for informational purposes, you may or may not find them useful for training your algorithm. In the current contest you can assume that each scan contains at least one tumor region. You should be aware that there is some variation in the structure names, for example names like "left lung", "LEFT_LUNG", "Lung Lt", etc refer to the same structure type. We didn't clear this up because these labels are present in the original DCM files that we didn't want to modify. The list of known name variations is given in the structure_dict.dat file, see details on this file later. It is important to know that the target "radiomics_gtv" structures may have the following name variations: "Radiomics_gtv", "radiomics_gtv2", "radiomics_gtv_nw", "radiomics_gtvr" The contour definition files describe the regions of interest in CSV format, one per line. If multiple lines are present in the file then it means that there are more than one instances of the same type of structure present on a given image. A line describes a contour shape as a polygon given by its points as a sequence of x,y,z coordinate values: x1,y1,z1,x2,y2,z2,x3,y3,z3,x4,y4,z4,... Note that although this format allows definition of polygons in a 3D space, in our case all z values are identical as the contour shape lies within a horizontal slice, the x-y plane. The points may be listed either in clockwise or counter-clockwise order within this plane. The coordinates are given in physical space, measured in millimeters. See the source code of the visualizer tool for information on how to convert between physical space and image space (mmToPixel() and pixelToMm() methods). Most of the marked up structures are simple polygons that are represented by the exterior boundary edge of its shape. This is sometimes not enough, see slices #39 - #42 of scan ANON_LUNG_TC072 for an example tumor region that contains a hole. To specify a shape that contains a hole the following procedure is used: If the external points are listed clockwise then the points of the internal ring (hole) are listed counter-clockwise (and vice versa). E.g. the shape on the image below can be specified by the following list of points: A,B,C,D,E,F,G,H,D,C,I,J,K,L.
Note that there are known errors in the contour definition files: tumor regions with very small areas (often less than one pixel) may appear, usually close to valid, larger tumor regions, but sometimes far from valid regions, they can appear even outside of the human body. These are measurement errors that don't significantly contribute to the total volume of valid tumor regions. DCM data version(You can skip this section if you are working with the PNG data version) Data corresponding to a scan is organized into the following file structure:
/<scan_id>
/CT
<image_name>.dcm
/RTst
<image_name>.dcm
Images DCM images can be viewed with Dicom viewers, there are plenty of free and commercial viewers available online. Dicom image files are in the /CT folder. Note that <image_name> is the original name of the file which does NOT correspond to the <slice_id> described above for the PNG-based data format. Also note that the <image_name> values may not be ordered in a way that corresponds to the topological order of image slices. The <slice_id> can be determined by the (0020.0013) Dicom tag (Instance Number). Image metadata Meta data are embedded in the .dcm images as standard Dicom tags. See the ct_tags.txt file for more information. Contours The location and shape of known marked up regions are described in a .dcm file in the RTst folder. All regions on all slices that belong to a scan are described in a single file. See the dcm_extract.py script for details on how to map the contour related meta data found in this dcm file to the <slice_id>, <structure_id> and contour names described above at the PNG based data format. In short, contours in the RTst file are correlated with image slices via the (0008.0018) (SOP Instance UID) tag of the CT files. These UIDs are used in the (0008.1155) (Referenced SOP Instance UID) tag within a contour sequences in the RTst file. The contours are defined in the (3006.0039) (ROI Contour Sequence) tag of the RTst file. <structure_id> corresponds to the (3006.0084) (Referenced ROI Number) tag of the contour sequence. The name of the contour sequence can be extracted from the (3006.0020) (Structure Set ROI Sequence) and (3006.0026) (ROI Name) tags. Note that contour descriptions are present only in the training data. Global files There are files that contain information for either all scans or for all scans that belong to a test set (example / provisional testing / system testing). These are relevant for both versions of the data.
DownloadsThe following files are available for download. It is recommended to verify the integrity of the large files before trying to extract them. SHA1(example_dcm.tgz) = 0de53a1ac2e5058fcd065ae9244705fbd5496d35 SHA1(example_dcm_sample.tgz) = 4f776c0187a2c387766861f13ab91ecbca2080e3 SHA1(example_extracted.tgz) = b1cca4f37ea3158af36764f1463c902c27dd5fb2 SHA1(example_extracted_sample.tgz) = 516defd625898972c1e9d58682d7a38fcc6a1888 SHA1(provisional_dcm_no_gt.tgz) = 473ff169865fff3048ccff56e02ccb7bb39320eb SHA1(provisional_extracted_no_gt.tgz) = a9c348f94095379eb9b06b6022af873a80307add Output FileYour output must be a CSV file where each line specifies a polygon that your algorithm extracted as a tumor region. The required format is: <scan_id>,<slice_id>,x1,y1,x2,y2,x3,y3,... Where <scan_id> and <slice_id> are the unique identifiers of a scan and an image, respectively, as defined in the Input Files section above. (Angle brackets are for clarity only, they should not be present in the file.) As is the case with contour definition files, the x and y values should be given in physical units (millimeters). Please note the difference between this format and contour definition files: here the z coordinates are not present. A sample line that describes a rectangular region extracted from slice #17 of scan ANON_LUNG_TC999: ANON_LUNG_TC999,17,80,0,100,0,100,10,80,10 The polygons need not be closed, i.e. it is not required that the first and last points of the list are the same. Your output must be a single file with .csv extension. Optionally the file may be zipped, in which case it must have .zip extension. The file must not be larger than 100MB and must not contain more than 1 million lines. Your output must only contain algorithmically generated contour descriptions. It is strictly forbidden to include hand labeled contours, or contours that - although initially machine generated - are modified in any way by a human. FunctionsThis match uses the result submission style, i.e. you will run your solution locally using the provided files as input, and produce a CSV or ZIP file that contains your answer. In order for your solution to be evaluated by Topcoder's marathon system, you must implement a class named LungTumorTracer, which implements a single function: getAnswerURL(). Your function will return a String corresponding to the URL of your submission file. You may upload your files to a cloud hosting service such as Dropbox or Google Drive, which can provide a direct link to the file. To create a direct sharing link in Dropbox, right click on the uploaded file and select share. You should be able to copy a link to this specific file which ends with the tag "?dl=0". This URL will point directly to your file if you change this tag to "?dl=1". You can then use this link in your getAnswerURL() function. If you use Google Drive to share the link, then please use the following format: "https://drive.google.com/uc?export=download&id=" + id Note that Google has a file size limit of 25MB and can't provide direct links to files larger than this. (For larger files the link opens a warning message saying that automatic virus checking of the file is not done.) You can use any other way to share your result file, but make sure the link you provide opens the filestream directly, and is available for anyone with the link (not only the file owner), to allow the automated tester to download and evaluate it. An example of the code you have to submit, using Java:
public class LungTumorTracer {
public String getAnswerURL() {
//Replace the returned String with your submission file's URL
return "https://drive.google.com/uc?export=download&id=XYZ";
}
}
Keep in mind that your complete code that generates these results will be verified at the end of the contest if you achieve a score in the top 10, as described later in the "Requirements to Win a Prize" section, i.e. participants will be required to provide fully automated executable software to allow for independent verification of the performance of your algorithm and the quality of the output data. ScoringA full submission will be processed by the Topcoder Marathon test system, which will download, validate and evaluate your submission file. Any malformed or inaccessible file, or one that exceeds the maximum file size (100 MB) or the maximum number of lines (1 million) will receive a zero score. If your submission is valid, your solution will be scored using the following algorithm. First for each scan of the test tp (true positive), fp (false positive) and fn (false negative) values are calculated for those slices where either ground truth regions are present, or regions extracted by your solution are present, or both. Here
These areas then are multiplied by the slice thickness (see tag (0018.0050) in the slice meta data files), and summed up for each scan, this gives the total TP, FP and FN volumes (measured in mm^3) for the scan. If TP is 0 then the score for this scan is 0. Otherwise the score for the scan is calculated the following way: The whole tumor volume T equals TP + FN. We define an FN' variable 'effective FN' as FN' = FN * T / (T - FN) = FN * T / TP Using this definition for FN', we define the error volume as E = FN' + FP Let A be the approximation of the surface area of the tumor: A = (36 * Pi * T^2)^(1/3) Let L be the acceptable error length threshold: L = 10 mm With these definitions the score for the scan is defined as scan_score = exp[ -(E / T + E / (L * A)) / 2] Finally avg_score is calculated as the arithmetic mean of all scan_score values of the test. Your overall score is 1000000 * avg_score. For the exact algorithm of the scoring see the visualizer source code. Example submissions can be used to verify that your chosen approach to upload submissions works. The tester will verify that the returned String contains a valid URL, its content is accessible, i.e. the tester is able to download the file from the returned URL. If your file is valid, it will be evaluated, and detailed score values will be available in the test results. The example evaluation is based on a small subset of the training data: 5 scans and corresponding ground truth that you can find in the example_extracted_sample.tgz (or example_dcm_sample.tgz) data package. Full submissions must contain in a single file all the extracted contour polygons that your algorithm found in all images of the provisional_extracted_no_gt.tgz (or provisional_dcm_no_gt.tgz) package. Detailed scores about full submissions will not be available, only a single value that represents the overall quality of your algorithm will be reported. Final ScoringThe top 15 competitors with non-zero provisional scores are asked to participate in a two phased final verification process. Participation is optional but necessary for receiving prizes. Phase 1. Code review Within 2 days from the end of submission phase you must package the source codes you used to generate your latest submission and send it to walrus71@copilots.topcoder.com and tim@copilots.topcoder.com so that we can verify that your submission was generated algorithmically. We won't try to run your code at this point, so you don't have to package data files, model files or external libraries, this is just a superficial check to see whether your system looks convincingly automatized. If you pass this screening you'll be invited to Phase 2. Phase 2. Online testing You will be given access to an AWS VM instance. You will need to load your code to your assigned VM, along with three scripts for running it:
Your solution will be subjected to three tests: First, your solution will be validated, i.e. we will check if it produces the same output file as your last submission, using the same input files used in this contest. (We are aware that it is not always possible to reproduce the exact same results. E.g. if you do online training then the difference in the training environments may result in different number of iterations, meaning different models. Also you may have no control over random number generation in certain 3rd party libraries. In any case, the results must be statistically similar, and in case of differences you must have a convincing explanation why the same result can not be reproduced.) Second, your solution will be tested against a set of new scans. The number and size of this new set of images will be similar to the one you downloaded as testing data. Third, the resulting output from the steps above will be validated and scored. The final rankings will be based on this score alone. Competitors who fail to provide their solution as expected will receive a zero score in this final scoring phase, and will not be eligible to win prizes. Additional Resources
General Notes
Requirements to Win a PrizeWeekly bonus prizes To encourage early participation, weekly bonus prizes will be awarded at 1 week and 2 weeks into the contest. To determine these prizes a snapshot of the leaderboard will be taken on 14th February and 21th February, at exactly 7*24 hours and 14*24 hours after the launch of the contest. In order to receve a weekly bonus prize you must have a non-zero score and be ranked 1st or 2nd on the current provisional leaderboard at the time the snapshot is taken. Within a day from the corresponding check point you must package the source codes you used to generate your latest submission and send it to walrus71@copilots.topcoder.com and tim@copilots.topcoder.com so that we can verify that your submission was generated algorithmically. We won't try to run your code at this point, so you don't have to package data files, model files or external libraries, this is just a superficial check to see whether your system looks convincingly automatized. Final prizes In order to receive a final prize, you must do all the following: Achieve a non-zero score in the top 15, according to system test results. Send your source codes for code review. See the "Final scoring" section above for details on these steps. Within 3 days of the end of the code review phase, you need to provide the copilot and administrator with VM requirements for your solution. 5 days from the dateyou receive the VM, the VM must be set up with your solution so Topcoder can easily validate and run it. Once the final scores are posted and winners are announced, the top 7 winners have 7 days to submit a report outlining your final algorithm explaining the logic behind and steps to its approach. The report must be at least 2 pages long and should contain:
If you place in the top 7 but fail to do any of the above, then you will not receive a prize, and it will be awarded to the contestant with the next best performance who did all of the above. | |||||||||||||
Definition | |||||||||||||
| |||||||||||||
Examples | |||||||||||||
| 0) | |||||||||||||
| |||||||||||||
This problem statement is the exclusive and proprietary property of TopCoder, Inc. Any unauthorized use or reproduction of this information without the prior written consent of TopCoder, Inc. is strictly prohibited. (c)2020, TopCoder, Inc. All rights reserved.