Challenge Overview
Introduction
Implement API for the following functions:- Get PDF information
- PDF image conversion
- Create PDF with text information retrieved from image using OCR
Background
The ultimate goal is to run the API as AWS Lambda, so even though this challenge doesn’t involve anything related to AWS at all, please keep this goal in mind and try your best to make sure there’s no compatibility issue when it’s time for us to move to AWS.
Architecture
Following is the complete architecture for this system, it also includes the AWS part which you can ignore in this challenge, but it would still be helpful for you to check it to get the idea of the big picture.Test Files
The sample PDFs for verification are listed below:- Sample PDF Japanese: If you don't understand Japanese, please use the following two files. This is a file with proper encoding.
- Sample PDF English1: File with proper encoding.
- Sample PDF English2: Files that do not have the proper encoding set.
The JSON file obtained by OCR of the sample PDF is as follows:
- Sample PDF Japanese OCR result JSON
- Sample PDF English1 OCR result JSON
- Sample PDF English2 OCR result JSON
Description
In this development challenge, the following functions need to be developed. Each function must be implemented according to the API specification described in “API Specs” section.1.Get PDF information API
Get the following information of the PDF file.- Whether text information is given
- Whether text information is given and appropriate encoding is set
- The purpose is to determine whether g_font_error occurs due to PDF.js getTextContent. The result of getTextConent has some problems. The str is “ and fontName is ‘g_font_error’. see. “Sample PDF English 2” corresponds to this.
- Whether the PDF is password protected and text information is not forbidden to be read
- General information in the following PDF
- Title
- Author
- Subtitle
- Keyword
- Created date
- Update date
- Created application
- PDF converted application
- PDF version
Page size- Page number
- File size
2.PDF image conversion API
Convert the specified PDF file to the PNG image format.For multi-page PDF, image files for the number of pages are output.
Conversion sequence diagram
3.PDF creation API with text information
OCR the specified image file and create a PDF with text information based on the OCR result. This means that the original image is a PDF with text overlaid with transparent text, with the font size of the image representing the text and the corresponding text appropriately adjusted.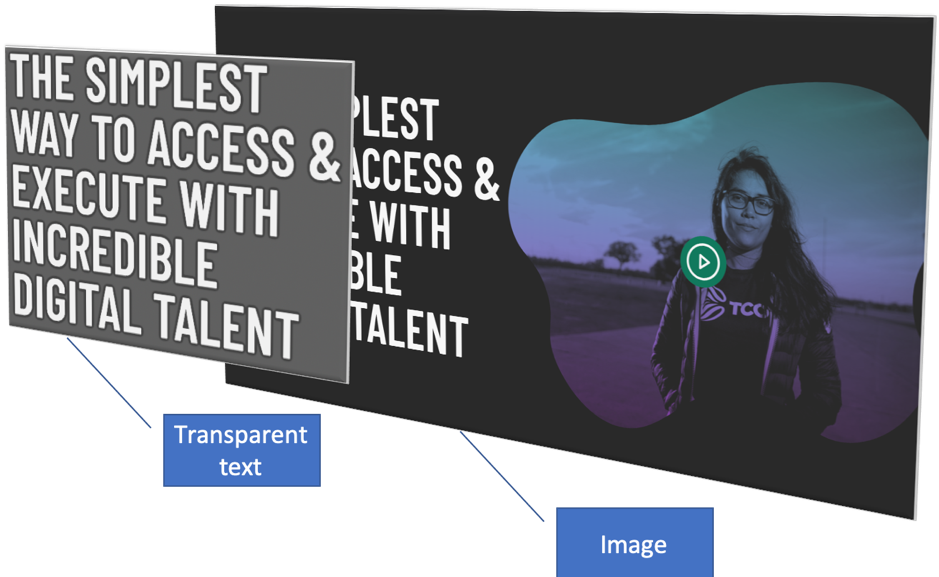
It is assumed that you can select and copy correctly when you select the range of the area that represents the character.
The created PDF must be able to be displayed as a web page on the browser (Chrome / Firefox) with PDF.js. Also, all text information recognized by OCR can be acquired by getTextContent of PDF.js.
Multiple image files are output as one PDF with the number of image files as the number of PDF pages.
There is no need to resize images when converting them to PDF.
Creation sequence diagram
4.OCR engine
We will provide a sample PDF of OCR using Google Vision API, so please use this JSON file for this development contest.- Sample PDF Japanese OCR result JSON
- Sample PDF English1 OCR result JSON
- Sample PDF English2 OCR result JSON
- Japanese
- English
It is not necessary to check Japanese in this development contest, but please implement it so that you can set it in a language other than English.
This development contest provides JSON files that are OCR from images, not directly from PDFs, to avoid PDF reading security issues. OCR from images is also performed in direct tasks.
5.Other
There is no problem using a commercially available open-source library for each API implementation. If you want to use an expensive library, please get our approval in advance.You may want to explore these libraries for implementation:
6.Use case
The final use case sequence will be posted as reference information.It is assumed that the PDF that cannot acquire text information is re-OCRed.
Use case sequence diagram
API Specs
- Swagger format
- API Spec details
- ankouPdfconverterV1Convert2imageJsonGet and ankouPdfconverterV1Convert2textpdfJsonGet are out of the scope of this challenge.
Limitations
The file size of the source resource cannot exceed 30MB.Final Submission Guidelines
Submission
Please zip and submit the following set of files:- Source code (Node.js 8.10 or Python 3.6)
- Readme
- Unit test
- Describe necessary information such as the execution method in the Readme