Challenge Overview
Background
From 25th January 2020, a challenge was run to generate a series of high quality financial forecasts for a consumer broadband brand. This challenge was called ‘CFO Forecasting - Financial Forecast Sandesh Brand 3’. It generated strong results on 3 of the 6 target variables across the two target products while the other 3 variables require further work.
This challenge is designed to improve on the accuracy and precision of these 3 lower performing forecasts to reduce MAPE and individual APE results.
The input data sets have been Normalised since the previous challenge as outlined below to support refinement.
The leading models from the initial challenge in January are shared as a possible foundation for refinement though these need not necessarily be used if superior results can be achieved though alternative approaches.
Challenge Objective
The objective of this challenge is to generate the highest accuracy predictions possible for the 3 financial variables outlined below, for each of the two products.The accuracy of the forecast must at least improve on the Threshold target quoted for each variable / product.
The model should be tailored to a 12-mth forecast horizon but must be extendable beyond this time period.
The accuracy of a prediction will be evaluated using MAPE (Mean Absolute Percentage Error) and maximum APE (Absolute Percentage Error) on the privatised data set over a period of 7 - 9 months.
Business context
The two products are broadband products:
-
Tortoise (legacy product, declining product, available everywhere) - slow download speeds.
-
Falcon (main product, reaching maturity, available in most of the country) - faster download speeds.
These two products do have an inter dependency since Falcon product is an upgrade of the earlier version, with the product growth of the later version dependent to a large extent on upgrading the customers from the earlier version. There is therefore a gradual move from Tortoise to Falcon.
The six variables are financial metrics
-
Gross adds – the number of new subscribers by product joining the brand during a month
-
Churn or Leavers – the number of subscribers by product who terminated service with the brand during that month
-
Net migrations – the number of subscribers who remained with the brand but moved to another product. This usually is an upgrade to faster broadband speed.
These three ‘discontinuous’ variables are seasonal - see Business insight section for more detail; can vary significantly from month to month; and are almost entirely dependent on the market, and competitor pressures at that point in time.
Challenge Thresholds and Targets
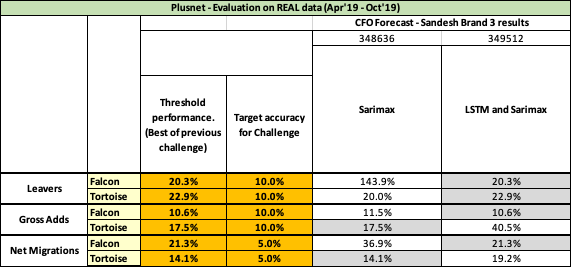
Models 348636 and 349512 are provided as foundation. These models can be used to baseline current performance on Privatised data set from which improvement will need to be made.
Note: Performance on Privatised data set may not correlate directly with performance on Real data set.
Your submission will be judged on two criteria.
-
Minimizing error (MAPE).
-
Achieving the Thresholds and Targets designated in the tables above.
The details will be outlined in the Quantitative Scoring section below.
Business Insights
The relationship between key financial variables
-
Closing Base for a Product = Volume Opening Base for that Product + Gross Adds – Leavers + Net Migrations to that Product
Net Migrations
Net migration is the difference in the number of existing customers with Sandesh Brand 3 that move onto and off a specific broadband product per month.
Net Migrations for Tortoise are a direct mirror image of Net Migrations for Falcon such that Net Migrations for Tortoise + Net Migrations for Falcon = 0 for each month.
This means that it should be possible to forecast both variables with equal accuracy and precision.
Trading Seasonality due to Accounting policies
These three variables are monthly trading performance figures and are calculated based on ‘trading months’ rather than ‘calendar months’. Each ‘trading month’ is artificially constrained to either 4 weeks or 5 weeks exactly, and are arranged in a 4 week, 4 week, 5 week pattern every 3 months. This artificial construct distorts the performance figures.
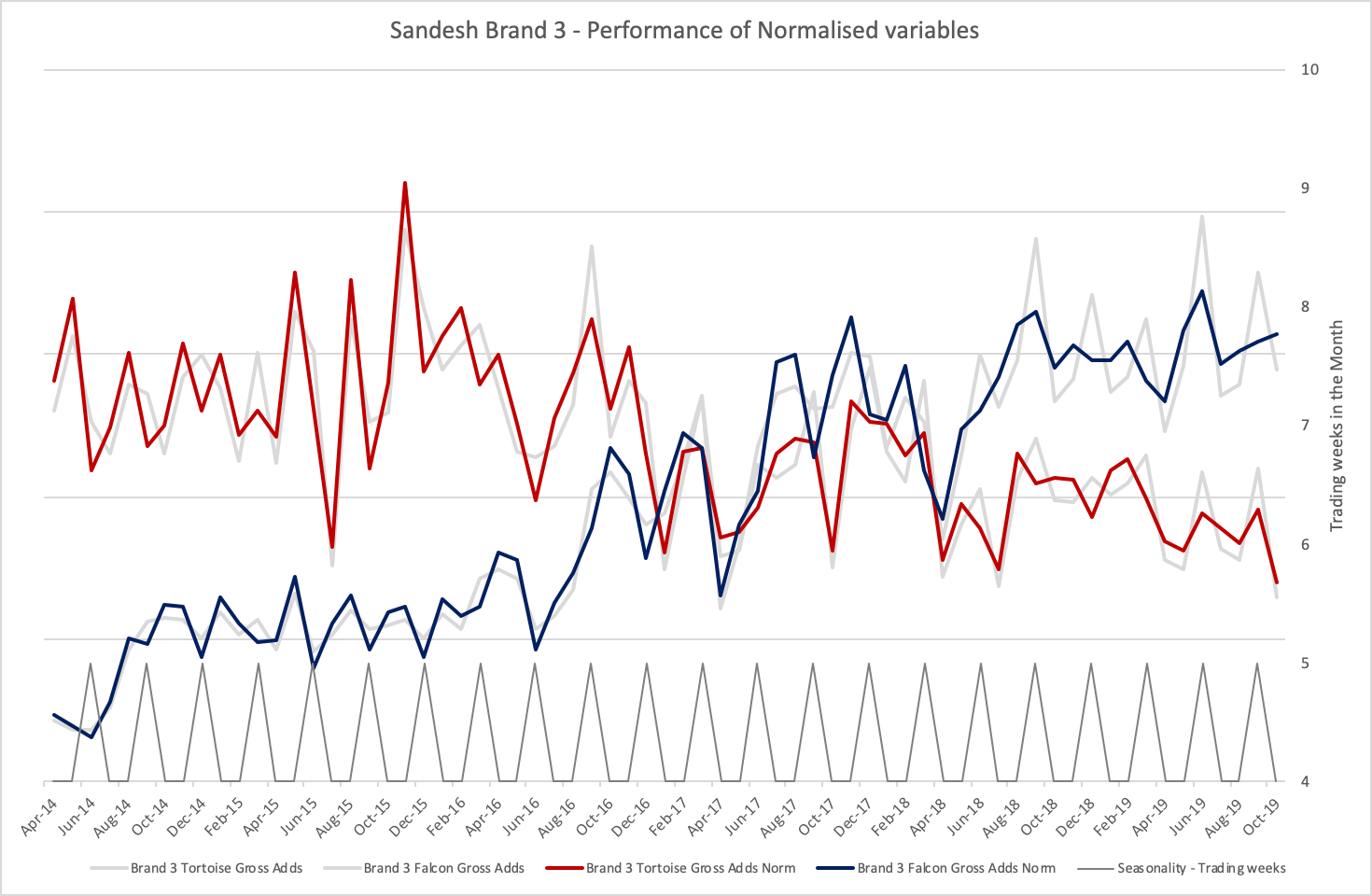
In the privatised data sets provided, the monthly performance has been Normalised to a consistent, standardised 4.3 week month. This approach significantly smooths the time series data set as demonstrated in the attached diagrams.
This is particularly true from August 2016. Prior to this date, the ‘trading seasonality’ is not so clear cut but the data set has been treated consistently throughout.
It is anticipated that this Normalisation of the variables will make it easier to forecast their performance and improve accuracy and precision.
Gross Adds for both Products - Real data set prior to Privatisation
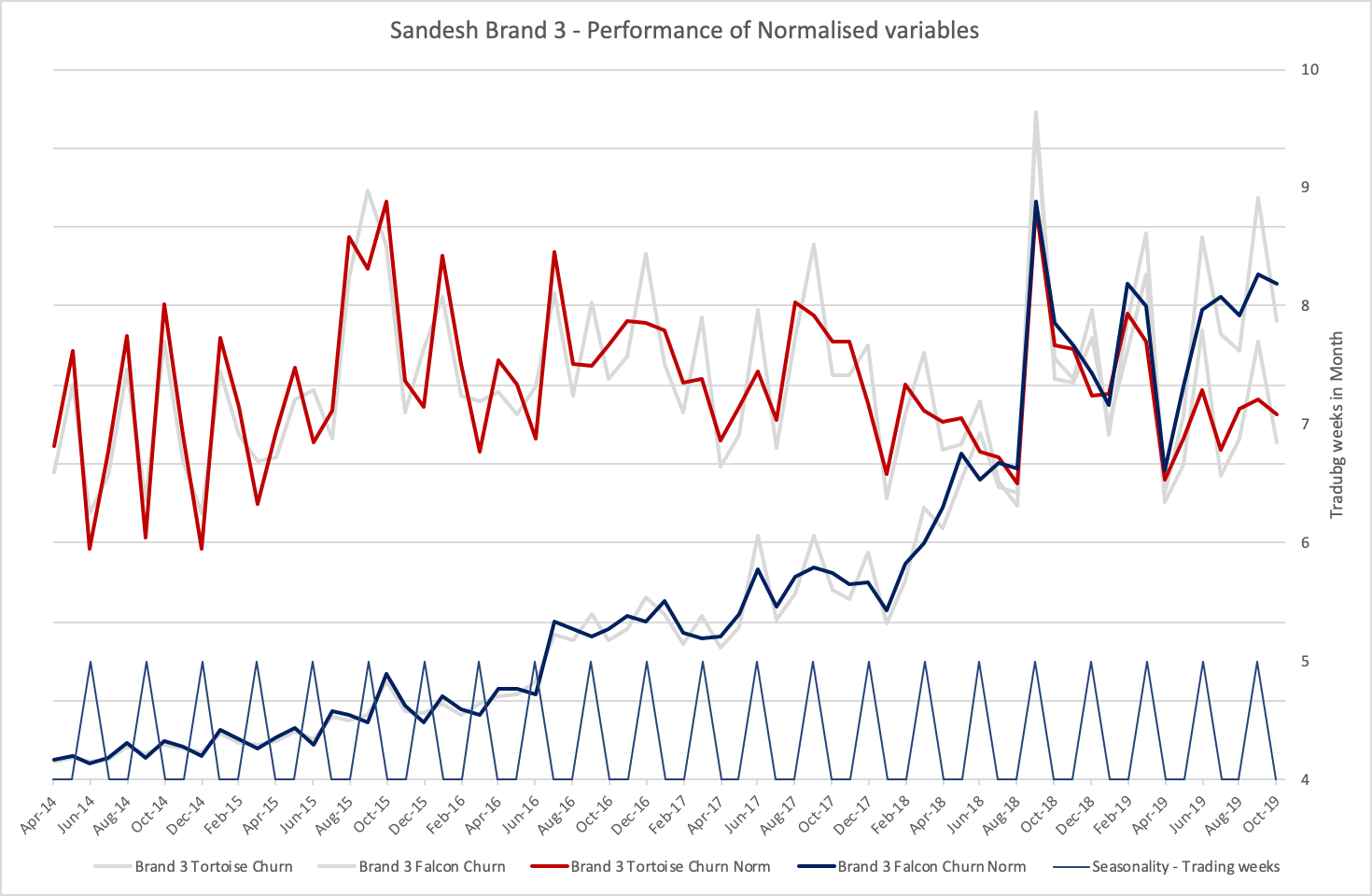
Churn (Leaver) for both Products - Real data set prior to Privatisation
Net Migrations for both products - Real data set prior to privatisation
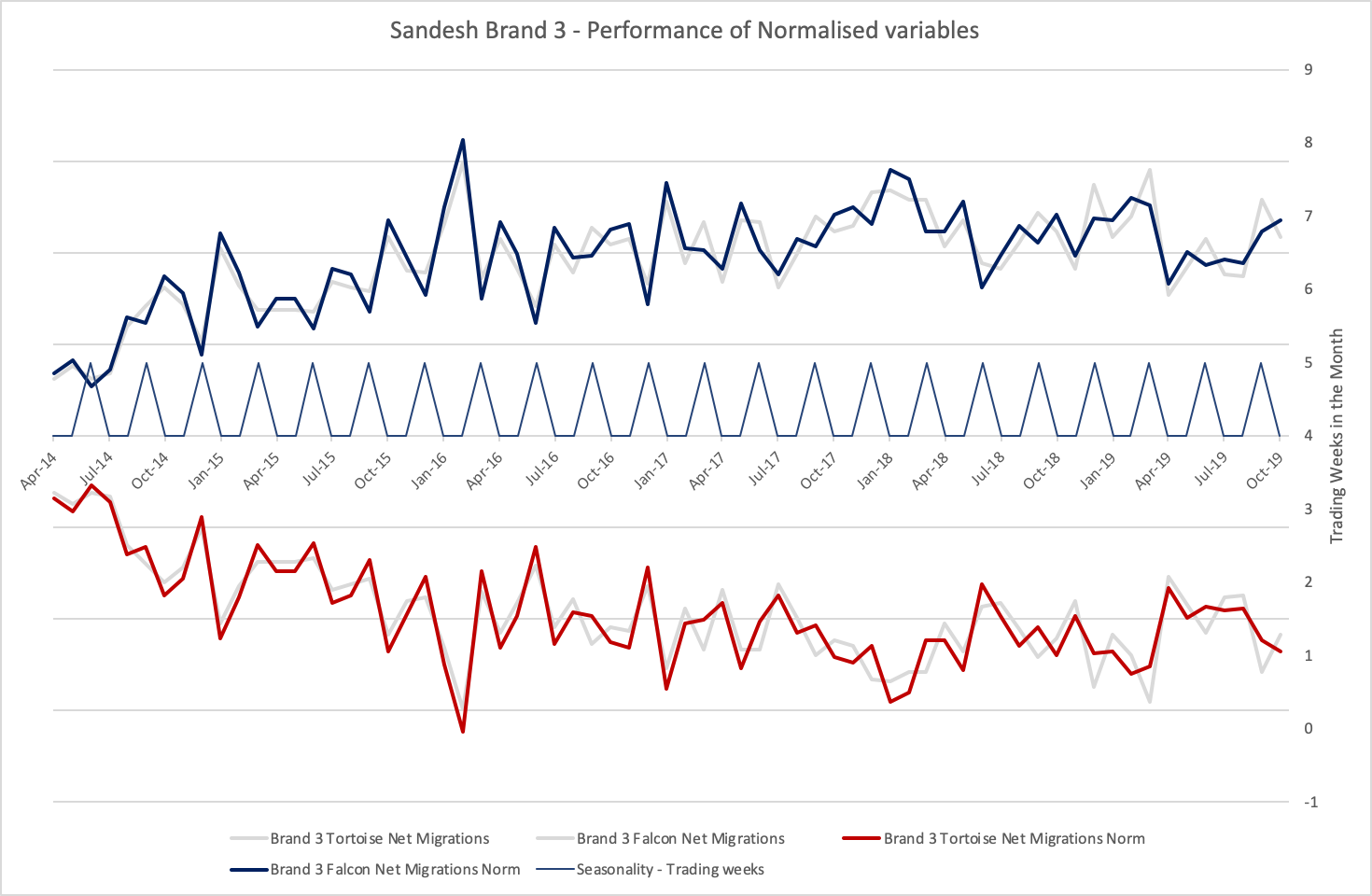
Note: Tortoise and Falcon are mirror images of each other
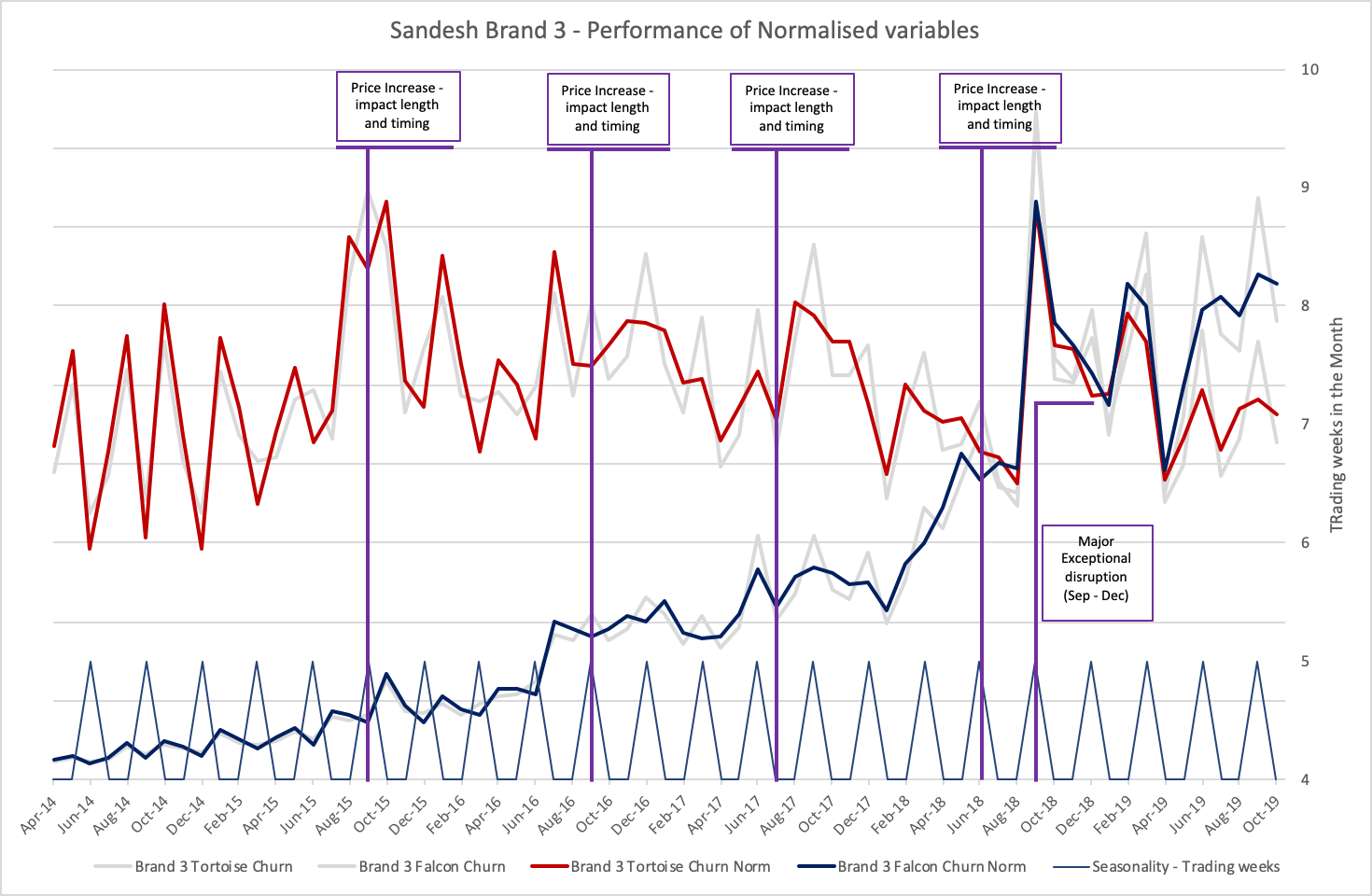
Churn / Leavers: Price increases impact and other external factors
Churn performance has been directly impacted by two external factors. It is assumed that building these appropriately into the Churn forecast, will improve forecasting performance. See diagram below for details.
These external factors are two fold
-
Regular Price Increases to the existing Customer base.
-
These increase have occurred once a year though exact timing varies year to year
-
The size of the price increase has however been the same every year
-
The impact of the price increase pre-dates the price rise (by 1 or 2 months) and extends for up to 5 months afterwards as customers react to the increase.
-
The impact of these regular increases needs to be factored into the model
Any treatment needs to be clearly documented and reproducible on the real data set.
-
A single, one-off ‘shock’ in Sept 2018.
-
This was a ‘one-off’ shock and will not be repeated in the future
-
The size of the impact has not been quantified - part of the challenge
-
The length of the impact is known to be from Sept 2018 to Dec 2018.
-
This ‘one-off’ impact overlaps with the price increase in 2018
-
The impact of this one-off shock needs to be estimated and treated so as not to impact future predictions.
Any treatment needs to be clearly documented and reproducible on the real data set.
Price Increase and ‘one-off’ impacts - see table below

Financial Year modeling:
Sandesh reports its financial year from April - March. This may contribute to seasonality based on financial year, and quarters (Jun, Sep, Dec, and Mar), rather than calendar year.
Anonymised and Privatised data set:
‘Z-score’ is used to privatise the real data.
For all the variables, following is the formula used to privatise the data:
zi = (xi – μ) / σ
where zi = z-score of the ith value for the given variable
xi = actual value
μ = mean of the given variable
σ = standard deviation for the given variable
Modeling Insight derived from previous challenges.
Optimise the algorithms by minimising RSME
It is recommended to optimise the models by minimising RSME, rather than MAPE because of the privatisation method used. It is strongly believed that minimising RSME will create the best model capable of being retrained on the real data set.
Final Submission Guidelines
Submission Format
You submission must include the following items
-
You are asked to provide forecasts for the following 12 months based on the given dataset. We will evaluate the results quantitatively (See below). The output file should be a CSV format file. Please use the “Generic LookupKey” values of the target variables and “Date” as the header.
-
A report about your model, including data analysis, model details, local cross validation results, and variable importance.
-
A deployment instructions about how to install required libs and how to run.
Expected in Submission
-
Working Python code which works on the different sets of data in the same format
-
Report with clear explanation of all the steps taken to solve the challenge (refer section “Challenge Details”) and on how to run the code
-
No hardcoding (e.g., column names, possible values of each column, ...) in the code is allowed. We will run the code on some different datasets
-
All models in one code with clear inline comments
-
Flexibility to extend the code to forecast for additional months
Quantitative Scoring
Given two values, one ground truth value (gt) and one predicted value (pred), we define the relative error as:
MAPE(gt, pred) = |gt - pred| / gt
We then compute the raw_score(gt, pred) as
raw_score(gt, pred) = max{ 0, 1 - MAPE(gt, pred) }
That is, if the relative error exceeds 100%, you will receive a zero score in this case.
The final MAPE score for each variable is computed based on the average of raw_score, and then multiplied by 100.
Final score = 100 * average( raw_score(gt, pred) )
MAPE scores will be 50% of the total scoring.
You will also receive a score between 0 and 1 for all the thresholds and targets that you achieve. Each threshold will be worth 0.033 points and each target will be worth 0.05 points. Obviously if you achieve the target for a particular variable you’ll get the threshold points as well so you’ll receive 0.083 points for that variable. Your points for all the variables will be added together.
Judging Criteria
Your solution will be evaluated in a hybrid of quantitative and qualitative way.
-
Effectiveness (80%)
-
We will evaluate your forecasts by comparing it to the ground truth data. Please check the “Quantitative Scoring” section for details.
-
The smaller MAPE the better.
-
Please review the targets and thresholds above as these will be included in the scoring.
-
-
Clarity (10%)
-
The model is clearly described, with reasonable justifications about the choice.
-
-
Reproducibility (10%)
-
The results must be reproducible. We understand that there might be some randomness for ML models, but please try your best to keep the results the same or at least similar across different runs.
-