Challenge Overview
Challenge Overview
Welcome to Infant nutrition OCR updates challenge. In this challenge, we aim to improve the edge cases for an OCR tool - namely handling decimal dots, percentage signs and units detection
Technology Stack
-
NodeJS / Python
-
Mongo
-
OCR, Tesseract, Tensorflow
Assets
Data extraction tool is available in the project repository. See forums for access to Gitlab. Read only access to the products database is provided in the forums. Copy the data to your local database for development. Also, a backup of product images is provided for reference.
Current status
Our tool reads the images from product records in the database and extracts nutrients and ingredients data.
Each product has several images and the tool determines how likely the image contains any ingredients/nutrients info (and logs this information in the console). Most of the products have at least one image with a full focus on ingredients/nutrients section on the product packaging. Here are two examples:

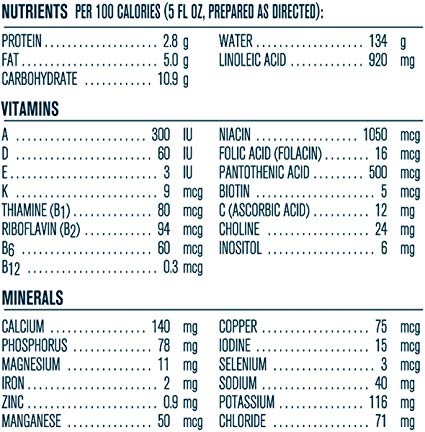
There can also be some products that don’t have any images with nutrients and ingredients data. In that case, the tool does not try any further extraction
Data for nutrients that is extracted is:
-
Name of nutrient
-
Amount (if available)
-
Unit (if available)
-
reference value the ingredients/nutrients refer to - is it per X g, X ml, per serving, per package, etc.
Extracted data is added to the product entry in the DB with the following structure:
{
nutrients: [{name,amount,unit, referenceValue}]
}
Current approach uses Tesseract to perform the OCR and then feeds the results to a keyword searcher to extract known nutrients. Previous approaches used Keras OCR and didn’t perform well (had more edge cases).
Tool also has a handy viewer that displays all products in the database along with their images and extracted nutrients
Individual Requirements
Main focus in this challenge is addressing these specific cases:
-
Decimal points are not detected (2.56 extracted as 256) or detected as 0 (2.56 extracted as 2056).
-
Percentage sign detected as 00 or not detected at all (30% detected as 3000)
-
Nutrient unit not detected at all, or nutrient missed completely
-
Lots of nutrients are missed completely - this might simply be due to lack of values in the dictionary, ocr issues, or parsing issues. See this example and this one.
NOTE: Ingredients extraction is working fine, no updates are needed in this challenge.
First and second point is mainly due to poor OCR results, while the last one is a mix of poor OCR and post processing step - not all units are there in the regex that is used to match nutrient amount+unit as text.
It is up to you to decide on the best strategies for improving the low accuracy score caused by the above mentioned issues. Here are some starting ideas:
-
Add image pre-processing (enlarge/rescale, convert to grayscale, blur, connected components analysis, etc)
-
Expand the keyword dictionaries,
-
Change the post-processing and parsing algorithm (add custom heuristics, update the regex search expression or remove it with a completely new approach)
-
Use a custom trained model for OCR
Review notes
Reviewers will need to spend a bit more time reviewing this challenge - besides reviewing the code changes to verify correctness you should pick 10 random products from the database and compare the tool performance with actual data in the images and note this in the review scorecard. Make sure to use the same set of products for all submissions to make the review consistent.
What to submit
-
Submit the full source code for the tool and a README with configuration, deployment and verification steps