Challenge Overview
Challenge Overview
Offset well analysis is the process of investigating and integrating historical drilling performance from neighboring wells into prospect ‘well’ design.
Traditional offset analysis is a time and resource intensive process that requires a lot of manual input and analysis to make various design decisions. Historical data is queried from a structured engineering and operation database consisting of data ranging from subsurface geology, drilling to production and end-of-well.
The goal of this project is to develop a machine learning algorithm that performs ranking of offset wells based on similarities and differences with the proposed well.
Task Detail
Designing the oil & gas wells is not an easy task. The engineer should understand the structures and parameters in the similar wells within the neighborhood of the new well’s location. Therefore, in this challenge, you are asked to develop a similarity search tool to facilitate the well design process. Without loss of the generality, this tool should follow a 2-stage design: (1) initialization/pre-computation and (2) online query.
The tool will be initialized by a set of wells and their features (e.g., shapes and rock formation). At this initialization stage, feel free to conduct some pre-computation to speedup the later query stage. Specifically, wells will be described by the following files:
-
CD_WELL.csv and CD_WELL_ALL.csv have the following variables:
-
1. Well’s common name
-
2. Well_id
-
3. loc_country-country of the well
-
4. is_offshore—Boolean variable about whether it’s a land or ocean rig?
-
5. Geo_latitude-location
-
6. Geo_longitude-location
-
7. Field_name-Region or location of the oil field
-
8. Target_formation-This is where we are targeting to reach-where the Oil Or gas is
-
9. Spud_Date-This means the date when drilling or the effort for well construction started
-
10. Well_purpose-Objective of drilling this well
-
11. Water_depth- In the oil and gas exploration and production (E&P) industry, deepwater is defined as water depth greater than 1,000 feet and ultra-deep water is defined as greater than 5,000 feet
-
12. Wellhead_depth: A wellhead is used for controlling pressure
-
-
CD_SURVEY_STATION.csv
-
This file focuses on the Well Shape
-
Variables: well_id, wellbore_id, md, tvd, inclination, azimuth, dogleg severity
-
well_id is the id of the well
-
Within a well_id, there could be multiple wellbores. Wellbore is the point of interest to us in terms of shape
-
You can see the shape of the well if you plot md vs inclination. Now how tortuous the well is and the quality, you would need azimuth, dogleg severity etc
-
-
-
CD_WELLBORE_FORMATION.csv
-
This file focuses on the Rock features
-
Variables: prognosed_md, prognosed_tvd (sort of equivalents to md, tvd from our file), wellbore_formation_id (id for the rock type), formation name
-
-
CD_PORE_PRESSURE.csv
-
Variable: tvd, pore_pressure, pore_pressure_emw (emw stands for equivalent mud weight). So you could either use pore_pressure or pore_pressure_emw
-
Pressure changes as a function of vertical depth, therefore here tvd is used and not md
-
-
CD_FRAC_GRADIENT.csv
-
Variables: frac_gradient pressure or frac_gradient_emw (either of them).
-
In this challenge, we can stick with emw here then use the same in pore pressure, so they should be in the same unit.
-
Depth is measured in tvd for the same reason as above.
-
Both pore pressure and frac gradient have ids. These ids are designed to reduce the continuity in using the real values and create some kind of categorical values and a range assigned. It is not required to use these ids.
-
You can download the well dataset from the forum.
Traditionally, an offset well analysis is run to gather the learnings from previous historical wells in the area and use those learnings to design a new well. The first step in that would be to find similar wells in the area. What constitutes similar is defined with respect to:
-
Shape of the well
-
Geological characteristic of the area where the well is drilled
Once similar wells are identified, then designs of each those wells are investigated with regards to some KPIs like cost etc. After that, a new well design is chosen.
Therefore, at the query stage, the user will provide the desired shapes of this new well. Well Shape is best seen graphically by plotting Measured Depth versus Inclination. Other features that add to the well shape is The azimuth and Dogleg severity. This defines how tortitous the well is. Your tool is supposed to return a ranked list of the most similar wells to the given input.
The figure below shows how to align the formation data from two wells by depth.
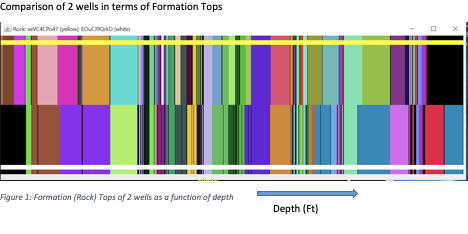
The key of your solution lies in the similarity measurement design. There will be 4 similarities: (1) Similarity based on Shape, (2 & 3) Two pressures (pore pressure and fracture pressure), and (4) Formation Tops. These 4 similarity measures shall be combined to give a single similarity value. We encourage you to explore different measurements and think about how to aggregate them. The similarity score must be between 0 and 1. 0 means no similarity at all; 1 means an exact match.
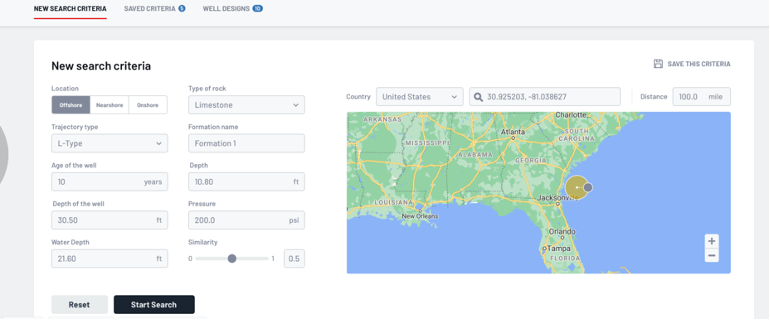
The User experience is as shown below. Formation, Well shape and pressures are entered for the proposed new well.
When you hit “Start Search”, what you get is as shown below
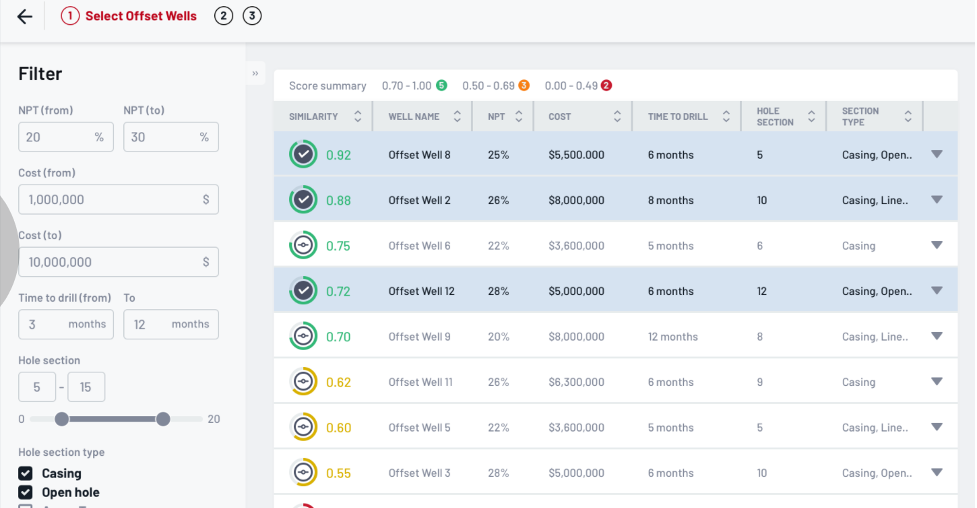
Expected Output. To evaluate your designed similarity measurement, we would like to ask you to find the most similar wells for each well. There are 26 wells in total. Please include the results in your submission with necessary visualization. We will eyeball the results with domain experts.
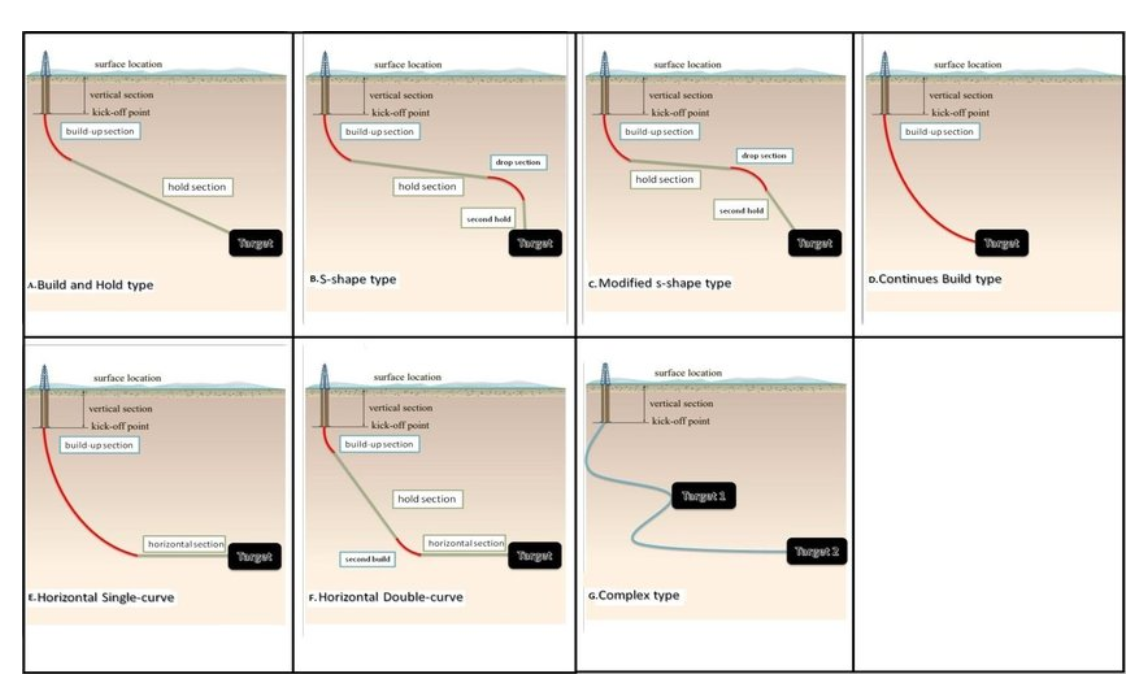
Popular Shapes
Final Submission Guidelines
Submission
You submission should contain:
-
A working Python codebase. It should be wrapped up as two command line entry points, one for initialization and one for online query. The well dataset filename and the query parameters must be a part of your command line calls.
-
A detailed document about your algorithm. How did you end up with your final designs? Have you tried other algorithms?
-
A detailed deployment instruction. What are the required libs? How to install them? How to run your codebase?
Judging Criteria
You will be judged on the quality of your algorithm and implementation, the quality of your documentation, and how promising it is as the base solution for the follow-up challenges. Note that the evaluation in this challenge may involve subjectivity from the client and Topcoder. However, the judging criteria will largely be the basis for the judgement.
-
Effectiveness (40%)
-
Is your algorithm effective, at least on the provided example wells?
-
Is your codebase runnable to other new queries?
-
Is your output on other new queries reasonably good?
-
-
Feasibility (40%)
-
Is your algorithm efficient, scalable to large volumes of data?
-
Is your algorithm easy to incorporate with the frontend development? Is there any related toolkit that we can use?
-
-
Clarity (20%)
-
Please make sure your report is easy to read- explain your basic line of thinking
-
Figures, charts, and tables are welcome.
-
Submission Guideline
We will only evaluate your last submission. Please try to include your great solution and details as much as possible in a single submission.