Crowdsourcing, Perfected.
Topcoder is a pioneer in crowdsourcing, with 20+ years of experience, and 325,000+ successful challenges in software development, data science/AI, UX design, and QA.
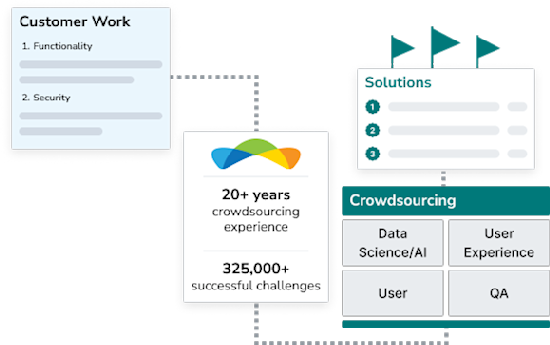
Crowdsourcing, Perfected.

Topcoder is a pioneer in crowdsourcing, with 20+ years of experience, and 325,000+ successful challenges in software development, data science/AI, UX design, and QA.











Revolutionize How You Get Work Done
Plug in Topcoder’s 1.9 million member global talent network to solve any technical problem.
Deliver your projects
Topcoder manages project delivery end-to-end, overseeing the global talent network to ensure quality.
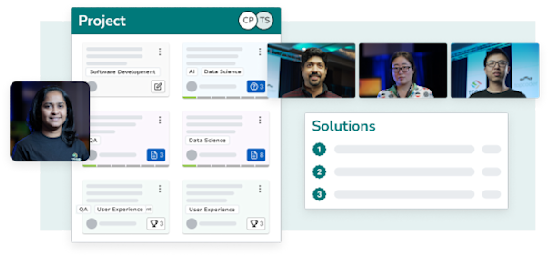
Deliver your projects
Topcoder manages project delivery end-to-end, overseeing the global talent network to ensure quality.
Harness our expertise
The talent network has deep experience with software development, data science/AI, UX design, and QA.
Harness our expertise
The talent network has deep experience with software development, data science/AI, UX design, and QA.
Innovate complex work
Top talent competes to provide innovative solutions to your most complex problems.
Innovate complex work
Top talent competes to provide innovative solutions to your most complex problems.
Engage directly with freelancers
Discover expert freelancers and engage with them directly.
Engage directly with freelancers
Discover expert freelancers and engage with them directly.
Accelerate with AI
Our AI-powered platform helps you create requirements, match talent, and automatically review solutions.
Accelerate with AI
Our AI-powered platform helps you create requirements, match talent, and automatically review solutions.
Customers Love Us!

The best part is the way Topcoder delivers in a short span of time.
User ExperienceSoftware Development

It goes without saying when you actually have diverse perspectives, people coming from different experiences, different ways of looking at the problem based on their experiences, the outcome is always better.
Data ScienceAI

If I’ve got an engineer lead developer, what better way to make sure that they are using their thought leadership than to give them the power of a global workforce?
User ExperienceSoftware Development

Topcoder for me is adding instant bandwidth capacity to my team without spending weeks and weeks.
Software DevelopmentQA

We broke it up into so many little pieces that the best folks from each of the 25 areas, they are the ones that solved each of these steps, and it all happened much faster than we ever would have done it on our own.
AIMachine Learning
The best part is the way Topcoder delivers in a short span of time.
User ExperienceSoftware DevelopmentIt goes without saying when you actually have diverse perspectives, people coming from different experiences, different ways of looking at the problem based on their experiences, the outcome is always better.
Data ScienceAI









And Our Talent Is Awesome!
- Member Since Jul 2001
 JustinTechnical Project ManagerCopilotJava.NETPythonNode.jsJavaScriptHTML
JustinTechnical Project ManagerCopilotJava.NETPythonNode.jsJavaScriptHTML 363 wins|
363 wins| Hobart, Australia
Hobart, Australia SpeaksEnglish
SpeaksEnglish - Member Since Jul 2013
 Nithya Kalyani JQA SpecialistCopilotSoftware Quality (SQA/SQC)JavaFlashHTMLAndroidJavaScript144 wins|Chennai, IndiaSpeaksTamil, English
Nithya Kalyani JQA SpecialistCopilotSoftware Quality (SQA/SQC)JavaFlashHTMLAndroidJavaScript144 wins|Chennai, IndiaSpeaksTamil, English - Member Since May 2018
 ViktóriaSenior Product DesignerCopilotFigmaUI/UX WireframingUser Interface (UI)Design BriefDesign StudioDesign Thinking104 wins|Budapest, HungarySpeaksEnglish, Hungarian
ViktóriaSenior Product DesignerCopilotFigmaUI/UX WireframingUser Interface (UI)Design BriefDesign StudioDesign Thinking104 wins|Budapest, HungarySpeaksEnglish, Hungarian - Member Since Jan 2010
 Monica MWeb DeveloperAI ExpertDockerExpress.jsJavaScriptNode.jsD3.jsPythonPrompt Engineering60 wins|Vienna, AustriaSpeaksEnglish
Monica MWeb DeveloperAI ExpertDockerExpress.jsJavaScriptNode.jsD3.jsPythonPrompt Engineering60 wins|Vienna, AustriaSpeaksEnglish - Member since Mar 2015
 Sergey PSoftware DeveloperCopilotJava.NETPythonNode.jsJavaScriptHTML170 wins|Benidorm, SpainSpeaksRussian, English, Spanish, Castilian
Sergey PSoftware DeveloperCopilotJava.NETPythonNode.jsJavaScriptHTML170 wins|Benidorm, SpainSpeaksRussian, English, Spanish, Castilian - Member Since Mar 2014
 AnanthData ScientistJavaScriptNode.jsSQLReact.jsPythonMongoDB97 wins|Bangalore, IndiaSpeaksEnglish, Tamil
AnanthData ScientistJavaScriptNode.jsSQLReact.jsPythonMongoDB97 wins|Bangalore, IndiaSpeaksEnglish, Tamil - Member Since Jul 2001JustinTechnical Project ManagerCopilotJava.NETPythonNode.jsJavaScriptHTML363 wins|Hobart, AustraliaSpeaksEnglish
- Member Since Jul 2013Nithya Kalyani JQA SpecialistCopilotSoftware Quality (SQA/SQC)JavaFlashHTMLAndroidJavaScript144 wins|Chennai, IndiaSpeaksTamil, English






Achieve high-quality outcomes with
Topcoder.
Achieve high-quality outcomes with Topcoder.