March 25, 2021
How to Extract Medical Information From Unstructured Data Using NLP

DURATION
20mincategories
Tags
share

Every medical organization uses their own Electronic Health Record (EHR) system to maintain patient records. Natural Language Processing (NLP) techniques are used in order to analyze those records and get very structured data.
As you are probably aware, NLP technology is growing quickly and vast amounts of new research papers have been published in arxiv.org.
In the field of medical science, you have to be familiar with a large amount of lingo such as symptoms, diagnosis, names of medications, etc…Therefore, one needs to maintain their medical records for better treatment or something similar, moreover, doctors will maintain more patient files which are seemingly unstructured. In this case, we can apply NLP on unstructured data and get useful information for the patient notes.
Use case
We can perform the operations below in the healthcare domain:
To improve and maintain clinical documentation
To create clinical notes using speech technology and get raw text data
To analyze the disease percentage for a year
To analyze a particular patient history of data
To increase awareness of patient health and to notify about current health report
Implementing NLP technology using two open source library👇🏻

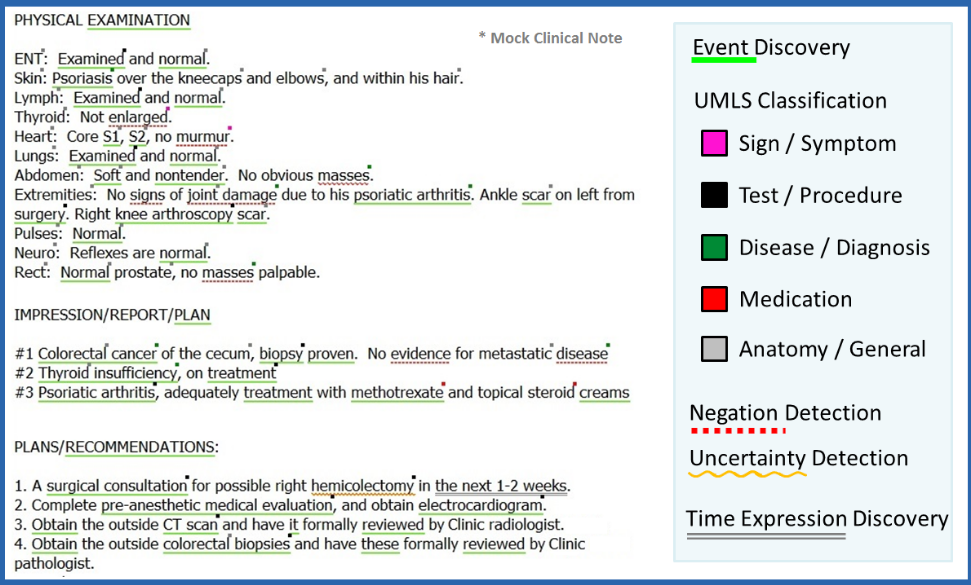
In the above picture, you may get some insights as to what are the components they have and what it will do. Let’s see this in detail.
What is Spark NLP?
Spark NLP was founded by John Snow Labs which was built on top of Apache Spark 2.4.4. It provides an easy API to integrate with your application. To use this API, you should know the programming languages Python or Java. Please follow the installation steps here. They provide a list of healthcare annotations, and are included as open-source. Also, this library covers many common NLP tasks including tokenization, stemming, lemmatization, part of speech tagging, sentiment analysis, spell checking, named entity recognition, etc…
AssertionLogReg
AssertionDL
Chunk2Token
ChunkEntityResolver
SentenceEntityResolver
DocumentLogRegClassifier
DeIdentificator
Contextual Parser
RelationExtraction
Example Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
//First import the Spark NLP library
from sparknlp.base
import *
from sparknlp.annotator
import *
from sparknlp.pretrained
import PretrainedPipeline
import sparknlp
//Start Spark Session with Spark NLP.
Start()
function has two parameters: gpu and spark23.
spark = sparknlp.start()
//Download a pre-trained pipeline
pipeline = PretrainedPipeline('explain_document_dl', lang = 'en')
//Your testing dataset
text = ""
" The Mona Lisa is a 16th century oil painting created by Leonardo.It's held at the Louvre in Paris.”””
//Annotate your testing dataset
result = pipeline.annotate(text)
//Check the results
result['entities']
Output: ['Mona Lisa', 'Leonardo', 'Louvre', 'Paris']

Why spark NLP libraries for healthcare application?
To perform any healthcare functionality you have to use a commercial extension of spark NLP. Regardless, you can use a free trial for some days and once the trial expires you will have to subscribe to a commercial extension.
Spark NLP provides clinical entity recognition, entity normalization, medical data relation extraction and assertion status detection. The other important thing is that we can use fifty types of pre-trained healthcare models that can recognize clinical symptoms, dosage name and strength, anatomy, and patient name and age.
What is Apache cTakes?
Apache cTakes was founded by the Mayo Clinic which was built using the Apache Unstructured Information Management Architecture (UIMA) engineering framework. The goal of cTakes is to be a world-class natural language processing system in the healthcare domain.You should install Java before installing cTakes. Installation steps here. They provide a list of components as below.
Sentence boundary detection
Tokenization (rule-based)
Morphologic normalization
POS tagging
Shallow parsing
Named Entity Recognition
Assertion module
Dependency parser
Constituency parser
Semantic Role Labeler
Coreference resolver
Relation extractor
Drug Profile module
Smoking status classifier
Unlike Spark NLP or NLTK library, Apache cTakes doesn’t perform general NLP functionality, therefore, it is partially designed for the healthcare domain which is directly used to implement functionality with your medical text data.
Example
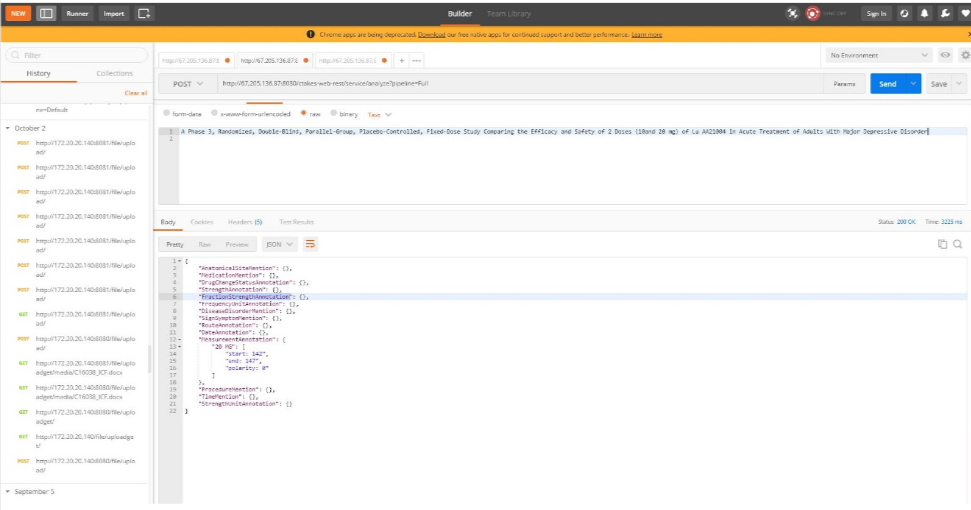
So how are they different?
| Spark NLP | Apache cTakes |
|---|---|
| Spark NLP has an OCR component to extract information from pdf and images. | Apache cTakes does not have an OCR component. |
| Spark NLP provides Python, Scala and Java API to access their functionality. | It only supports Java. |
| They maintain all pre-trained models in their model hub where we can get a lot of pre-trained models. Check them out here | It does not have any model hub to maintain pre- trained models. |
| It has some NLP functionality other than the health care related components. | Apache cTakes components are specifically trained for the clinical domain only. |
Final Words
NLP will give you a new way to perceive and see data in a well organized manner. I would suggest you use Spark NLP library because NLP has many data preprocessing pipelines like stemming, sentence detection, POS tagger, etc… Also they have a pre-trained model so we can transfer learning.
However, if you would like to use open source, you should go with Apache cTakes library.
Here is a simple comparison with other libraries. If you would like to proceed with a paid option (without coding and setup), you can choose Amazon comprehend medical which gives high accuracy and has more options for the healthcare domain. Try it out with your data and see the results.