January 26, 2021
Top Five Websites for Generating Datasets for Machine Learning Projects

DURATION
15mincategories
Tags
share

When you endeavour on a machine learning project, data plays a key role, therefore, we should know how to generate data.
There are third party websites that provide a huge amount of data. The only thing we need to know is how to preprocess data as per our use case. Most profitable organizations like Google and Facebook have huge amounts of data which requires them to build more accurate models.
Data is precious. Some companies even sell their data for machine learning purposes. You can become rich in the field of data science if you have the raw data for machine learning.
Let us see how to generate data using third party websites that have huge amounts of data that can be easily downloaded.
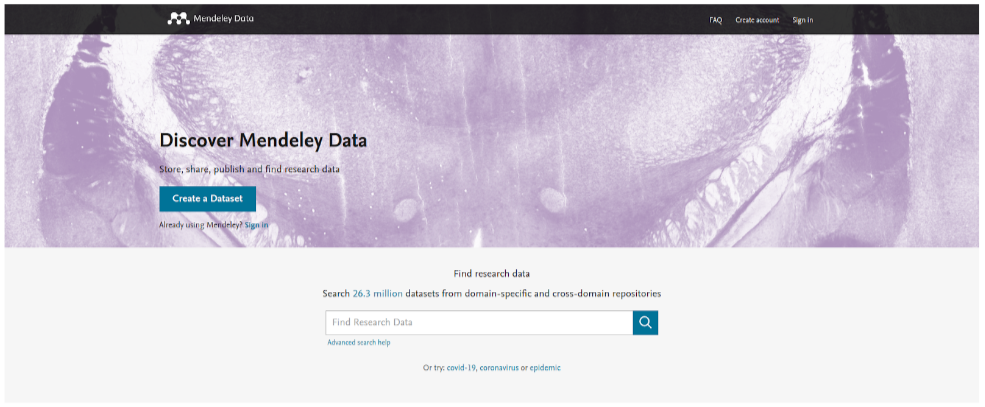
Mendeley Data
This website provides a unique ODI for each version of your dataset. From the above picture you can see that the search field must be used to search data. Consequently, If you have a huge amount of data, you can save your data and share with others in a more secure way. Through this, we may not be required to pay money to store TB level data. It owns around 26.3 million data so we can be confident that our data will be more secure.
Topcoder
https://www.topcoder.com/thrive/search?title=datasets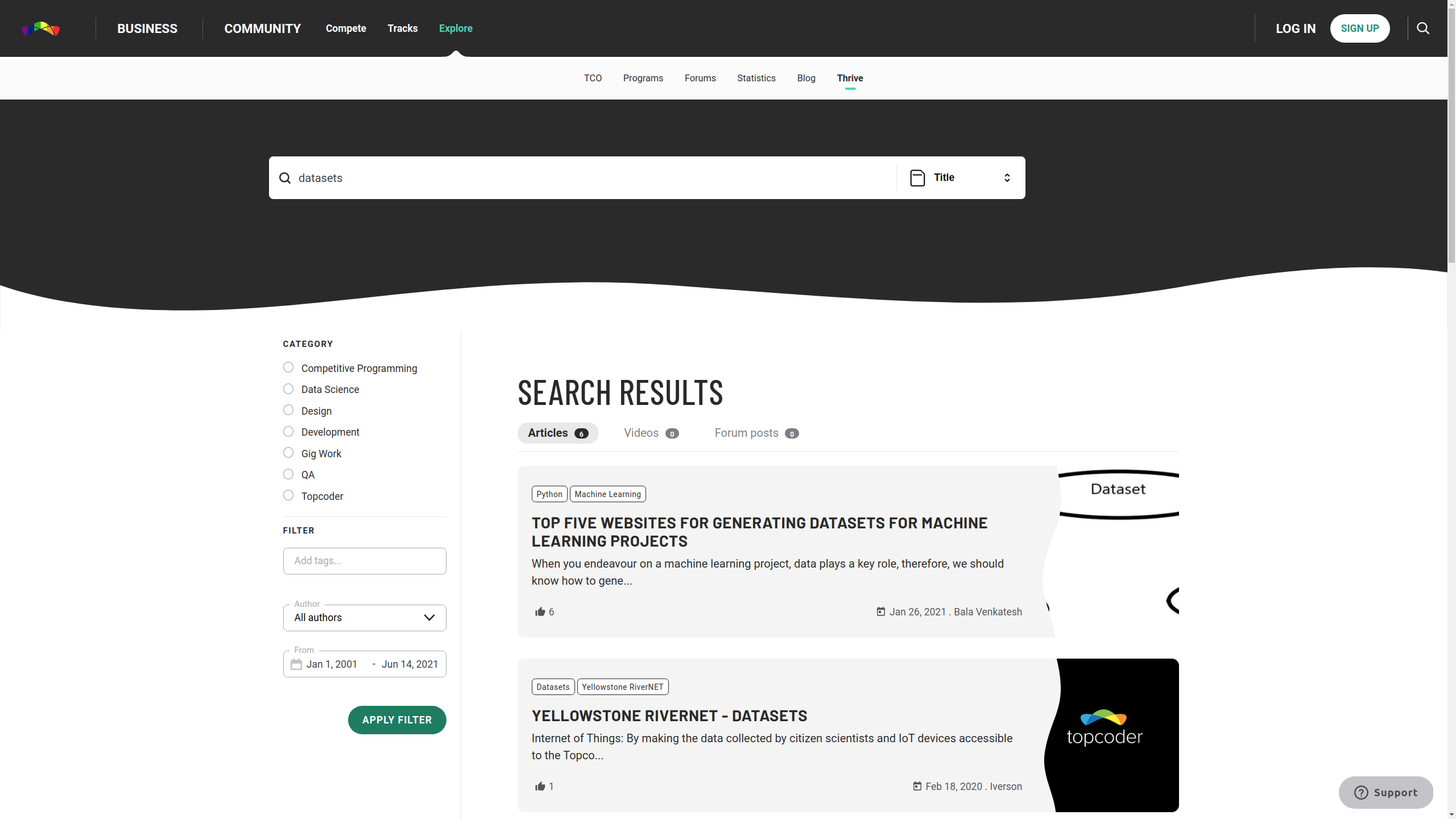
With Topcoder Datasets you have access to high-quality labeled data, some of which you can’t find anywhere else. We also provide the tools to shape your own data. These datasets are intended to help you shape and strengthen algorithmic models and sharpen your data science abilities along the way.
Start by exploring our favorite datasets to get a better understanding of what they contain and if interested, try pairing them up with your algorithms or others found in Models & Algos.
Deepmind
https://deepmind.com/research?filters={"tags":["Datasets"]}
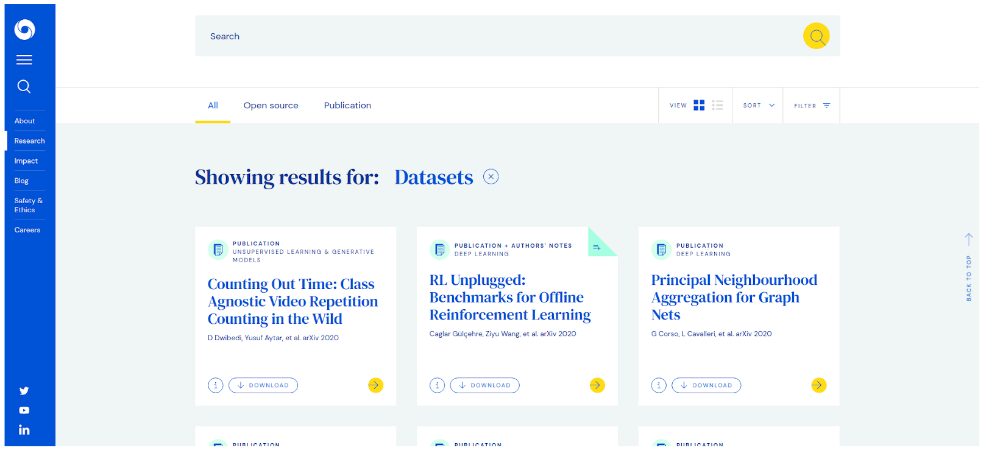
Deepmind is a research company which was founded in September 2010 and later acquired by Google in 2014. On Deepmind we can get a lot of video datasets in kinetics. It also provides some useful research papers. Recently, they have implemented alphfold, which will detect protein structure, which is a very big milestone in Artificial Intelligence.
https://datasetsearch.research.google.com/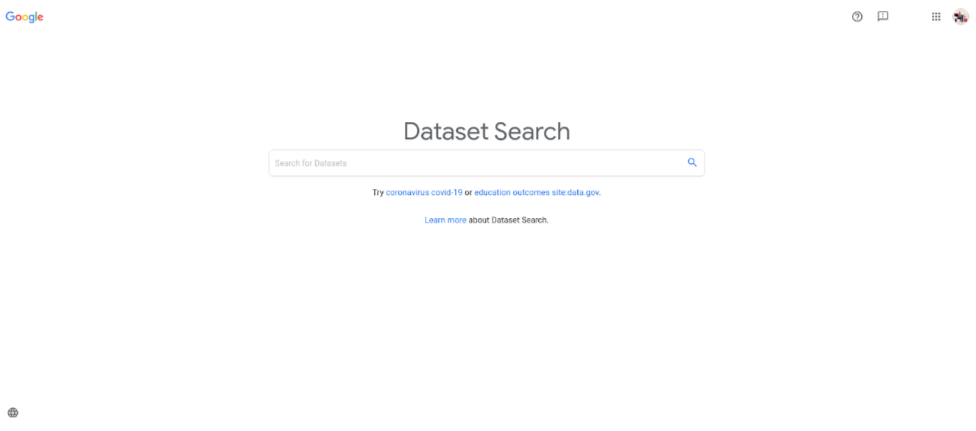
Google has a dataset search engine tool you can use to search more than twenty-five million publicly available datasets. The dataset result contains description of the dataset contents as well as author citations. Google dataset publisher uses schema.org to describe their metadata. If you would like to publish your own dataset then you can use schema.org to publish your dataset with metadata.
Limitation:
It does not provide any API to download or search the dataset.
Amazon
https://registry.opendata.aws/

Amazon has a huge amount of data. Also they have Facebook Data for Good, NASA Space Act Agreement and the Amazon Sustainability Data Initiative. If you want to add your dataset check out how here. The whole dataset is not maintained by the AWS team, some third party individuals and companies are working on this. For more information check out the Github
Microsoft
Microsoft provides a beta version of open data. We can search for data as categories which is very useful to get an accurate dataset. In total, they have ten categories of dataset such as healthcare, computer science, and physics. You can easily directly copy them to Azure-based virtual machines and data science virtual machines. We can find related research papers around the dataset. This data is completely maintained by Microsoft researchers, industry partners, and academic advisers.
Conclusion
I hope this third party website list is helpful for your machine learning project. If you are a beginner, I suggest you try the Kaggle website where you can get a notebook with a dataset. It will be more helpful for you to start playing with a machine learning project.